|
| 恾1丂朰媝嬋慄偵傒傞俀庬椶偺挿婜婰壇 乮Ebbinghaus,1885傪夵曄乯 |
摿廤丂妛廋幰杮埵偺嫵堢偺幚尰丄妛傃偺幙偺岦忋傪栚巜偟偨戝妛嫵堢偺DX峔憐乮偦偺侾乯
帥郪丂岶暥乮壀嶳戝妛丂妛弍尋媶堾嫵堢妛堟嫵庼乯
丂嬤擭嫵堢尰応偱偼丄栴宲偓憗偵夵妚偑媮傔傜傟丄壗偐怴偟偄偙偲偵庢傝慻傑側偗傟偽側傜側偄偲偄偆埫栙偺僾儗僢僔儍乕偺傕偲丄廫暘帪娫偑側偄拞偱條乆側庢慻傒偑帋峴偝傟偰偄傞傛偆偵尒偊傑偡丅
丂偦傕偦傕嫵堢偺惉壥偼丄怴偨側帠嬈傗僇儕僉儏儔儉偺摫擖丄慻怐夵曇傪峴偆偙偲帺懱偱偼側偔丄偦傟偵傛傝亙妛惗偑朷傑偟偄曽岦偱曄梕偟偨偐偳偆偐亜偱杮棃昡壙偝傟傞傋偒傕偺偱偡丅怴偨側庢慻傒偺幚巤偺傒偱偼惉壥傪帵偡偙偲偵偼側傝傑偣傫丅傑偨丄恖偺峴摦曄梕傪僨乕僞偱帵偡偙偲偼憐憸埲忋偵崲擄側偙偲偱偡丅僄價僨儞僗偵婎偯偔嫵堢乮Evidence Based Education乯偼堦挬堦梉偵偱偒傞偙偲偱偼偁傝傑偣傫丅
丂嬤擭ICT偺恑曕偲忣曬抂枛偺晛媦偵傛傝丄條乆側戝検偺峴摦僨乕僞乮價僢僌僨乕僞乯偑庡偵柉娫婇嬈偵廤栺偝傟傞忬嫷偑惗傑傟偰偄傑偡丅偟偐偟丄恖娫偺峴摦僨乕僞偵尷偭偰偼丄扨弮偵廤傔傜傟偨價僢僌僨乕僞偐傜怴偟偔桳塿側忣曬傪尒弌偡偙偲偼傎傏晄壜擻偲尵偊傞丄尨棟揑栤戣偑偁傝傑偡丅
丂埲壓丄偦偺栤戣偵愢柧傪壛偊丄偦傟傪夝寛偟杮妛偱柧妋側惉壥偑摼傜傟巒傔偨丄怴偨側倕儔乕僯儞僌傪徯夘偟傑偡丅
丂彫拞妛峑偵堦恖堦戜偺忣曬抂枛偑摫擖偝傟杮奿揑側塣梡偑巒傑偭偰偄傑偡偑丄婛偵尰応偐傜偼丄ICT傪妶梡偟偰傕崱傑偱埲忋偺惉壥偑摼傜傟側偄偲偄偆惡偑弌偰偄傑偡丅偦傟偼戝妛偵偍偄偰傕摨條偱丄偙傟傑偱懡偔偺戝妛偱條乆側倕儔乕僯儞僌偑摫擖偝傟偰偄傑偡偑丄杮妛偱傕廬棃偺倕儔乕僯儞僌偼妛惗偺棙梡棪偼掅偔丄妛惗偺惉愌偵帵偝傟傞柧妋側惉壥偼曬崘偝傟偰偄傑偣傫偱偟偨丅
丂堦曽丄杮妛偱2019擭搙偵杮奿摫擖偝傟偨儅僀僋儘僗僥僢僾丒僗僞僨傿乮MicStudy乯偼丄帺傜妛傇堄梸傪挿婜偵傢偨傝妋幚偵乮桳堄偵乯忋徃偝偣傞偙偲傗塸岅偺岅渂椡傪岦忋偝偣傞偙偲傪乽曐徹乿偱偒傞抜奒偵擖偭偰偄傑偡丅捈嬤偱偼丄倕儔乕僯儞僌偺妛廗検偲憤崌揑塸岅椡乮GTEC乯偺惉愌偺娫偵桳堄側娭學惈偑柧妋偵帵偝傟傑偟偨乮徻嵶偼僾儗僗儕儕乕僗梊掕乯丅傑偨丄2019擭搙偵偼柉娫婇嬈偱昡壙偑崅偄擔杮e-Learning傾儚乕僪偱暥晹壢妛戝恇徿傪庴徿偟丄幮夛幚憰偑奼戝偟丄2021擭搙偵偼慡崙偺侾枩恖傪挻偊傞妛廗幰偵擭娫傪捠偠偰倕儔乕僯儞僌偲僼傿乕僪僶僢僋偑採嫙偝傟偰偄傑偡丅偙偺傛偆偵丄嫵堢暘栰偵偍偄偰柧妋側惉壥傪僨乕僞偱帵偡偙偲偼丄ICT傗抂枛偺妶梡偩偗偱幚尰偱偒傞傕偺偱偼偁傝傑偣傫丅妛惗偺堄梸傪岦忋偝偣傞偨傔偵偼恖娫偺堄梸乮妛弍揑偵偼摦婡偯偗乯偵娭偡傞抦幆傗棟榑偑昁梫偱偁傝丄岠棪揑側妛廗傪幚尰偡傞偨傔偵偼丄恖娫偺婰壇儊僇僯僘儉偵娭偡傞嵟怴偺抦幆偲棟榑偺棟夝偑昁梫偱偡丅媡偵丄ICT偵壛偊偰恖娫偵娭偡傞壢妛揑棟夝偲棟榑偑偁傟偽柧妋側惉壥傪妛廗幰偵採嫙偱偒傞偲偄偊傑偡丅
丂倕儔乕僯儞僌偺嵟戝偺崲擄偼丄宲懕偱偒側偄揰偵偁傝傑偡丅廬棃偺倕儔乕僯儞僌偼丄僐儞僥儞僣傪暘偐傝傗偡偔丄柺敀偔丄鉟楉偵掓帵偡傞偙偲偱妛廗幰偺堄梸傪崅傔傞偙偲偵椡揰偑抲偐傟偰偄傑偡丅偦傟備偊摫擖摉弶偼妛廗幰偼堄梸揑偵妛廗偵庢傝慻傓偙偲偑偱偒傑偡丅偟偐偟丄恖娫偼梌偊傜傟傞曄壔偵偼偡偖偵姷傟偰偟傑偄丄堄梸偼斾妑揑偡偖偵棊偪丄擇搙偲忋傝傑偣傫丅僎乕儉嬈奅偱傕僎乕儉傪俁偐寧埲忋宲懕偟偰傕傜偆偙偲偵戝偒側暻偑偁傞偲偄傢傟傞偙偲偐傜偡傟偽摉慠偱偟傚偆丅
丂偦傟偵懳偟偰傕偆堦偮恖偺峴摦傪堷偒婲偙偡忣曬偑帺暘帺恎偵娭偡傞曄壔忣曬偱偡丅妛弍揑側媍榑偼徣偒傑偡偑丄乽帺暘偑曄壔偟偰偄傞偲偄偆幚姶傪惗傒弌偡忣曬傪媮傔偰恖偼峴摦傪婲偙偡乿偲峫偊傞偲傎偲傫偳偺峴摦傪愢柧偱偒傑偡丅暘偐傝傗偡偔尵偊偽丄曌嫮偡傞偙偲偱丄帺暘偺惉愌偑忋偑偭偰偄偔忣曬傪宲懕偟偰採嫙偱偒傟偽丄妛惗偼曌嫮傪宲懕偡傞偲峫偊傜傟傑偡丅
丂栤戣偼丄擔乆曄壔偡傞妛廗惉壥傪妛惗偵帵偡偙偲偑偱偒傞偐偵偁傝傑偡偑丄偦偺懌妡偐傝偑20擭埲忋慜偺愽嵼婰壇尋媶偐傜弌偰偒傑偟偨丅
丂MicStudy偼丄壢妛尋媶旓曗彆嬥偺婎斦尋媶A偱俀搙嵦戰傪庴偗傞側偳偟偰幚梡壔偝傟丄2018擭搙偺撪妕晎SIP乮愴棯揑僀僲儀乕僔儑儞憂憿僾儘僌儔儉乯傊偺嵦戰偵傛傝幮夛幚憰偺摴偑奐偐傟傑偟偨偑丄偦偺弌敪揰偼丄幚尡怱棟妛偺婰壇尋媶偵偁傝傑偡丅偄傢備傞抦幆偼挿婜婰壇偵懳墳偟丄挿婜婰壇偼丄尠嵼婰壇偲愽嵼婰壇偺俀庬椶偵暘椶偝傟傑偡丅恾侾偺僄價儞僌僴僂僗偺朰媝嬋慄傪椺偵偲傟偽丄偡偖偵徚偊偰偟傑偆堦栭捫偗偺妛廗岠壥偑尠嵼婰壇偱偁傝丄堦斒揑側婰壇偼偙偪傜偵奩摉偟傑偡丅懠曽丄侾偐寧宱偭偰傕巆偭偰偄傞丄幚椡偵懳墳偡傞婰壇偑愽嵼婰壇偱偁傝丄尵岅擻椡傕偦偺婎斦偼愽嵼婰壇偲偝傟傑偡丅偙偙偱拲堄偡傋偒揰偼丄椉婰壇偑慡偔堎側傞摿挜傪帩偭偰偄傞偙偲偱偡丅椺偊偽丄尠嵼婰壇偼偡偖偵徚偊傑偡偑丄愽嵼婰壇偼徚偊偢偵悢偐寧扨埵偱曐帩偝傟傑偡丅愽嵼婰壇偑憐憸埲忋偵挿婜偵帩懕偡傞偙偲偼丄悢懡偔偺尋媶偱徹柧偝傟偰偍傝[1][2]丄偦偙偱偼摓掙怣偠傜傟側偄嬃堎揑側恖娫偺婰壇擻椡偑帵偝傟偰偄傑偡丅傑偨丄妎偊傛偆偲偟偰曌嫮偡傞偐丄尒棳偡傛偆偵曌嫮偡傞偐傕尠嵼婰壇偵偼妋幚偵塭嬁偟傑偡偑丄愽嵼婰壇偱偼傎偲傫偳塭嬁偟傑偣傫丅偦偺懠丄壛楊偵敽偄尠嵼婰壇擻椡偼掅壓偟傑偡偑丄愽嵼婰壇偱偼崅楊幰偲戝妛惗偱婰壇擻椡偵戝偒側嵎偼弌偰偙側偄側偳嫽枴怺偄帠幚偺曬崘偑懡悢偁傝傑偡丅
恾1丂朰媝嬋慄偵傒傞俀庬椶偺挿婜婰壇
乮Ebbinghaus,1885傪夵曄乯
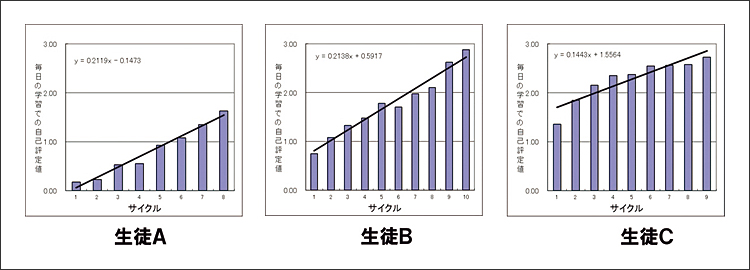
丂偙偺俀庬椶偺婰壇偼尩枾側幚尡憖嶌傪偟側偗傟偽嬫暿偡傞偙偲偼偱偒側偄偨傔丄堦斒揑側僥僗僩偱惓妋側幚椡傪應掕偡傞偙偲偼偱偒傑偣傫丅塸扨岅傪曌嫮偡傞拞偱丄幚椡儗儀儖偱恎偵偮偄偨偐偳偆偐暘偐傜偢丄晄埨傪怈偊側偄尨場偼偙偙偵偁傝傑偡丅
丂傑偨丄婰壇偼偡偖徚偊傞偐傜壗搙傕斀暅妛廗傪偟偰丄偁傞掱搙妎偊偨傜師偺儁乕僕偵妛廗傪恑傔傞妛廗朄偑悇彠偝傟傞偙偲偑偁傝傑偡偑丄偙偺妛廗朄偼堦栭捫偗偺曌嫮偵偼桳岠偐傕偟傟傑偣傫偑丄幚椡僥僗僩傗岅妛偺帋尡偵偼旕忢偵旕岠棪偱偁傞偙偲傕柧傜偐偵側偭偰偄傑偡[1]丅
丂偡偖徚偊傞堦栭捫偗偺妛廗岠壥偲幚椡偺曄壔傪暘棧偡傞偨傔偵偼丄妛廗偲僥僗僩偺僀儞僞乕僶儖傪妛廗僐儞僥儞僣偛偲偵惂屼偡傞昁梫偑偁傝傑偡丅幚偼丄偙偺乽偄偮乿妛廗偲僥僗僩傪峴偆偺偐偲偄偆忦審偺岠壥偼憐憸傪挻偊傞戝偒側岠壥傪帩偭偰偍傝丄偦傟傪惂屼偣偢偵廂廤偝傟偨價僢僌僨乕僞偵偼丄偦偺岠壥偑戝偒側僑儈偲側偭偰傑偲傢傝偮偔偙偲偵側傝丄偦偙偐傜桳堄媊側忣曬偼尨棟揑偵拪弌偱偒傑偣傫丅
丂椺偊偽丄億僀儞僩僇乕僪傪巊偭偰攦偄暔傪偡傞偲丄扤偑丄偄偮丄壗傪峸擖偟偨偺偐偲偄偆峸攦峴摦僨乕僞偑廤栺偝傟傑偡丅戝検偺峸攦峴摦偺價僢僌僨乕僞偼10擭埲忋慜偐傜廤栺偝傟偰偄傑偡偑丄偦偙偐傜廬棃埲忋偺峴摦梊應偼摫偗側偄棟桼偑偁傝傑偡丅壖偵柧擔丄偁傞恖偑價乕儖傪攦偆妋棪傪悇掕偡傞掱搙偺梊應傪偟偨偄応崌傪峫偊偰傒傑偡丅梊應偵偼丄柧擔偺婥壏傗攦偆恖偺擭廂丄惈暿丄偦偟偰侾偐寧偁偨傝偺價乕儖峸擖検摍傪曄悢偲偡傞儌僨儖傪棫偰梊應偡傞偺偑堦斒揑偱偟傚偆丅偟偐偟丄幚嵺偺偲偙傠丄崱擔偦偺恖偑價乕儖傪侾働乕僗峸擖偡傟偽柧擔攦偆妋棪偼偐側傝彫偝偔側傝傑偡丅媡偵丄侾偐寧慜偵價乕儖傪峸擖偟丄偦傟埲崀峸擖偟偰偄側偗傟偽柧擔峸擖偡傞妋棪偼偐側傝崅偔側傝傑偡丅偮傑傝丄椶帡偟偨僀儀儞僩傪偄偮宱尡偟偰偄偨偺偐偵傛傝丄恖偺峴摦偼戝偒偔曄傢傞傢偗偱偡丅偦偟偰乽偄偮乿偲偄偆忦審偼柍悢憐掕偝傟丄偦偺悢偼恖椶偺悢傪挻偊傞傕偺偵側傝傑偡丅偦傟備偊丄戝検偺峴摦僨乕僞傪AI側偳偵偐偗偰傕堦掕偺孹岦傪拪弌偡傞偙偲偼尨棟揑偵崲擄偱偁傞偲峫偊傜傟傑偡丅
丂妛廗僀儀儞僩傕摨條偱丄柧擔偺帋尡偱丄偁傞妛廗幰偑偁傞栤戣偵惓摎偡傞妋棪傪悇掕偡傞応崌丄崱擔偦偺栤戣傪妛廗偟偰偄傟偽惉愌偼崅偔側傝傑偡偑丄侾偐寧慜偵曌嫮偟偨偩偗偱偁傟偽惉愌偼掅偔側傝傑偡丅偲偙傠偑丄偦偺侾偐寧慜偺偝傜偵侾擭慜偐傜彮偟偢偮妛廗傪偟偰偄偨応崌偱偁傟偽丄帋尡傑偱偺侾偐寧娫曌嫮偟偰偄側偔偰傕惉愌偼崅偔側傞偲峫偊傜傟傑偡丅
丂偮傑傝丄柧擔偺帋尡偱摿掕偺栤戣偵惓摎偡傞妋棪傪悇掕偡傞偨傔偵偼丄擭扨埵偱偦偺栤戣偵懳偡傞妛廗棜楌傪攃埇偟丄偦偺忦審偛偲偵惉愌偺忋徃僷僞乕儞傪悇掕偟偰偍偔昁梫偑偁傝傑偡丅
丂杮妛偵摫擖偝傟偨MicStudy偼丄傑偝偵TOEIC偱昁梫偲偝傟傞俀愮岅埲忋偺塸扨岅傪栐梾偟丄偦偺堦偮堦偮偵偮偄偰丄偄偮丄偳偺傛偆偵妛廗傗僥僗僩傪峴偆偺偐偲偄偆徻嵶側僗働僕儏乕儖傪擭扨埵偱惗惉偟丄偦傟偵懳墳偟偰斀墳僨乕僞傪廤栺偡傞偙偲偱丄帪宯楍忦審偑偦傠偭偨戝検偺妛廗僨乕僞乮崅惛搙嫵堢價僢僌僨乕僞乯傪惗傒弌偡偙偲傪壜擻偵偟偰偄傑偡丅
恾俀丂俁恖偺崅峑惗偺俁廡娫偺塸扨岅妛廗岠壥
丂帪娫忦審偺塭嬁傪攔彍偡傞偨傔偵偼丄幚尡怱棟妛偺暋嶨側幚尡寁夋朄傪僔僗僥儉偵慻傒擖傟傞昁梫偑偁傝傑偡偑丄偙偺揰傪僋儕傾偡傞偙偲偵傛傝恾俀偺傛偆側惉愌偺忋徃偑屄暿偵昤偒弌偣傞傛偆偵側傝傑偟偨丅恾偼俁恖偺崅峑惗偑丄侾擔10暘懌傜偢偺塸扨岅妛廗傪俁廡娫宲懕偟偰摼傜傟偨僨乕僞偐傜惉愌偺忋徃傪壜帇壔偟偨傕偺偱偡丅偙偺傛偆側惉愌偺曄摦偑屄暿偵僼傿乕僪僶僢僋偝傟傟偽偮傑傜側偄倕儔乕僯儞僌偱傕妛惗偼妛廗傪宲懕偡傞傛偆偵側傝傑偡丅
丂岅妛椡偺岦忋偵偼丄妛廗傪宲懕偱偒傞偟偔傒偑昁梫偱偡偑丄MicStudy偼丄忋婰偺傛偆側僼傿乕僪僶僢僋傪屄暿偵採嫙偡傞偙偲偱妛惗偑妛廗傪宲懕偱偒傞忬嫷傪惗傒弌偣偨傢偗偱偡丅
丂偝傜偵傕偆堦偮丄MicStudy偺妛廗検偲憤崌揑塸岅椡乮GTEC偺惉愌丗儕僗僯儞僌亄儕乕僨傿儞僌乯偺娫偵桳堄側娭學惈偑専弌偱偒偨棟桼偲峫偊傜傟傞偺偑丄屄暿嵟揔壔張棟偺幚憰偱偡丅
丂MicStudy偼偡傋偰偺塸扨岅傪栐梾偟丄偦傟偧傟偵偮偄偰妛廗偲僥僗僩偺僞僀儈儞僌傪偦傠偊傞偙偲偑偱偒傑偡丅偦傟偵傛傝堦掕偺儁乕僗偱奺栤戣偵懳偡傞惉愌傪掕揰娤應偡傞偙偲偑壜擻偵側偭偰偄傑偡丅塸扨岅傗娍帤偺惉愌偼堦掕偺儁乕僗偱妛廗偝傟偨応崌捈慄揑偵忋徃偟偰偄偔偙偲偑丄10擭埲忋偺尋媶偱柧傜偐偵側偭偰偄傑偡丅偦傟備偊栤戣偛偲偵廂廤偝傟傞惉愌偺曄摦僨乕僞偐傜丄幚椡儗儀儖偺摓払搙傪惓妋偵悇掕偡傞偙偲偑悽奅偱弶傔偰壜擻偵側傝傑偟偨丅偦偺悇掕抣偑嵟崅揰傪挻偊偨偲敾掕偝傟偨塸扨岅偑妛廗儕僗僩偐傜徚偊偰偄偔丄屄暿嵟揔壔偺婡擻偑杮奿揑偵壱摥偟巒傔偰偄傑偡丅妛廗幰偵偼丄屄暿嵟揔壔張棟偺寢壥丄夝愅偛偲偵妛廗偡傋偒巆傝偺塸扨岅悢偑慟尭偟偰採帵偝傟丄堄梸岦忋偵婑梌偟偰偄傑偡丅
丂嬤擭丄屄暿嵟揔壔偝傟偨妛傃偑廳帇偝傟偰偄傑偡偑丄偦傕偦傕惓妋偵妛廗幰偺幚椡儗儀儖偺惉愌偑悇掕偱偒側偗傟偽丄岆偭偨儗僐儊儞僨乕僔儑儞偑側偝傟傞忬嫷偑惗傑傟丄妛廗幰偑庢曉偟偺偮偐側偄忬嫷偵娮偭偰偟傑偆壜擻惈偼斲傔傑偣傫丅彮側偔偲傕丄廬棃偺傛偆側侾搙偺僥僗僩偺惉愌偐傜幚椡傪惓妋偵悇掕偡傞偙偲偼晄壜擻偱偡丅
丂杮妛偺幚慔僨乕僞僒僀僄儞僗僙儞僞乕偵偼丄朿戝側廲抐揑妛廗僨乕僞偩偗偱側偔丄怱棟広搙僨乕僞偑廤栺偝傟偰偍傝丄偦傟偼曮偺嶳偲側偭偰偄傑偡丅杮妛偱尒偄偩偝傟偨GTEC偺摼揰偲MicStudy偺妛廗検偺桳堄側娭學惈偑丄MicStudy傪摫擖偟偨崅峑偺塸専偺摼揰偵傕尒偄偩偝傟偰偄傑偡丅妛廗幰偺晧壸傕彮側偔乮侾擔10暘掱搙乯丄掅僐僗僩偱岅妛椡傪忋偘傜傟傞岅妛嫵堢偺婎杮僣乕儖偲偟偰丄懠戝妛傗愱栧嫵堢傊偺摫擖傪悇恑偟偰偄偔梊掕偱偡丅
丂ICT偺妶梡傗丄AI張棟偑摫擖偝傟傞偩偗偱偼丄嫵堢偺惉壥傪尩枾偵昡壙偡傞偙偲偼崲擄偲尵傢偞傞傪摼傑偣傫丅恖娫偺梸媮傗妛廗摍偵娭偡傞丄僨乕僞巙岦偺嫵堢怱棟妛偺抦幆傗僨乕僞廂廤偺僗僉儖丄偦偟偰恀棟傪捛媶偡傞惤幚側壢妛幰偺帇揰偑側偗傟偽恖娫偺峴摦曄梕傪壜帇壔偡傞偙偲偼偱偒側偄偲尵偊傑偡丅
丂懠曽丄ICT傗忣曬抂枛傪巊偆偙偲側偔丄偙偺傛偆側抦幆廗摼偺巟墖傪幚尰偡傞偙偲偑偱偒側偄偙偲偼丄壩傪尒傞傛傝傕柧傜偐偱偡丅抦幆廗摼偵偮偄偰偼丄屄恖儗儀儖偺妛廗巟墖傪僐儞僺儏乕僞偲崅惛搙嫵堢價僢僌僨乕僞偱姰慡偵巟墖偱偒傞抜奒偵擖偭偨偲尵偊傑偡丅堦恖偱傕偱偒傞抦幆廗摼偼僐儞僺儏乕僞偵擟偣丄抁帪娫偱岠棪揑偵廗摼傪懀偡偙偲偵傛傝嬻偄偨帪娫傪丄憂憿揑巚峫椡偺堢惉傗懱尡揑妛廗丄庡懱揑妛傃側偳丄恀偵崅師側恖娫偺擻椡偺堢惉偵怳傝岦偗傞偙偲偑壗傛傝廳梫偵側偭偰偔傞偲峫偊偰偄傑偡丅偦偺傛偆側嫵堢偺幚尰傪変乆偼栚巜偟偰偄傑偡丅
| 嶲峫暥專 | |
| [1] | 帥郪岶暥乮曇挊乯,2021丂崅惛搙嫵堢價僢僌僨乕僞偱曄傢傞婰壇偲嫵堢偺忢幆乗儅僀僋儘僗僥僢僾丒僗働僕儏乕儕儞僌偵傛傞抦幆廗摼偺岠棪壔乗丂晽娫彂朳 |
| [2] | 帥郪岶暥,2016 愽嵼婰壇偲妛廗偺幚慔揑尋媶丂懢揷怣晇丒嵅媣娫峃擵乮娔廋乯乽塸岅嫵堢妛偲擣抦怱棟妛偺僋儘僗億僀儞僩丂亅彫妛峑偐傜戝妛傑偱偺塸岅妛廗傪峫偊傞亅乿杒戝楬彂朳, pp.37-55. |